
工程技术:在智能体优先的世界中利用 Codex
原文
重点摘要
- 从应用逻辑、测试、CI 配置、文档、可观察性、内部工具 — 全都是由 Codex 编写的。
- 当软件工程团队的主要工作不再是编写代码,而是设计环境、明确意图、构建反馈回路,从而使 Codex 智能体能够可靠地工作。
我们从一个空的 Git 代码仓库开始
- 初始架构 — 包括代码仓库结构、CI 配置、格式化规则、包管理器设置、应用框架 — 是在一小套现有模板的指导下,由 Codex CLI 使用 GPT‑5 生成的。就连指导智能体如何在代码仓库中工作的初始 AGENTS.md 文件本身也是由 Codex 编写的。
- 五个月后,该代码仓库已经拥有约一百万行代码,从应用逻辑、基础设施、工具、文档到内部开发者工具应有尽有。
重新定义工程师的角色
- 在实践中,这意味着采用深度优先的工作方式:将更大的目标拆解为更小的构建模块(设计、代码、评审、测试等),提示智能体去构建这些模块。
- 而人类工程师则总是介入这项任务并追问:"究竟还需要什么样的能力,我们又该如何让这个能力对智能体来说既清晰可读又可强制执行?"
- 为了推动 PR 的完成,我们会指示Codex 在本地审核其自身的更改,在本地和云端请求额外的特定智能体审查,对任何人工或智能体给出的反馈做出响应,并循环往复,直到所有智能体审核人员都满意为止(这实际上是一个Ralph Wiggum 循环)。人类可以审核 Pull Request(合并请求),但并非必须这样做。随着时间的推移,我们已将几乎所有的审核工作调整为用智能体对智能体的方式来处理。
提高应用程序的可读性
- 努力通过应用程序的 UI、日志和应用指标等内容对 Codex 直接可读,从而为智能体增加更多功能。
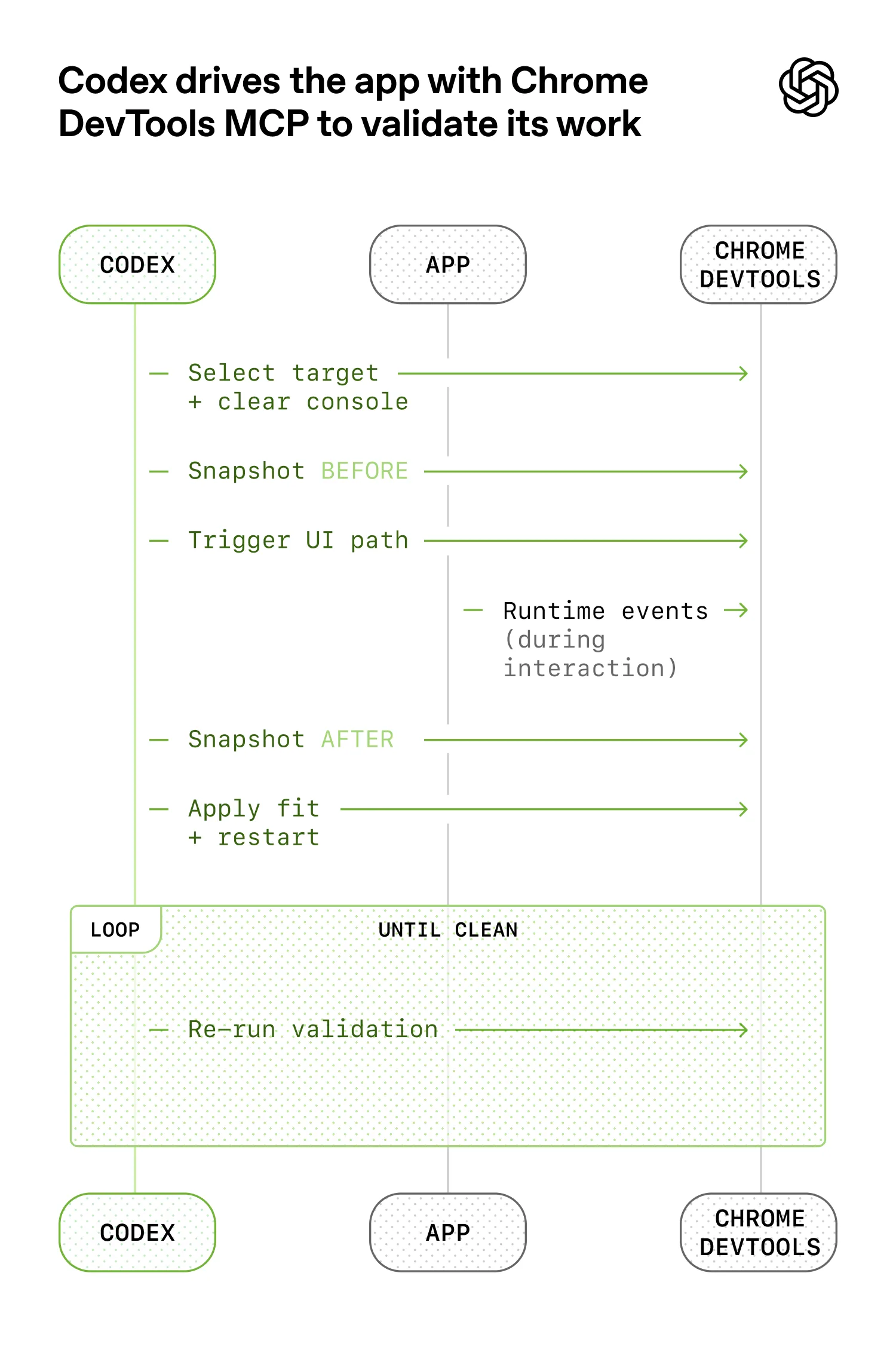
- 令应用程序可以根据 git worktree 启动,因此 Codex 可以为每次更改启动并驱动一个实例。我们还将Chrome DevTools 协议接入智能体运行时,并创建了用于处理 DOM 快照、屏幕截图和导航的技能。这使 Codex 能够复现错误、验证修复,并直接推理 UI 的行为。
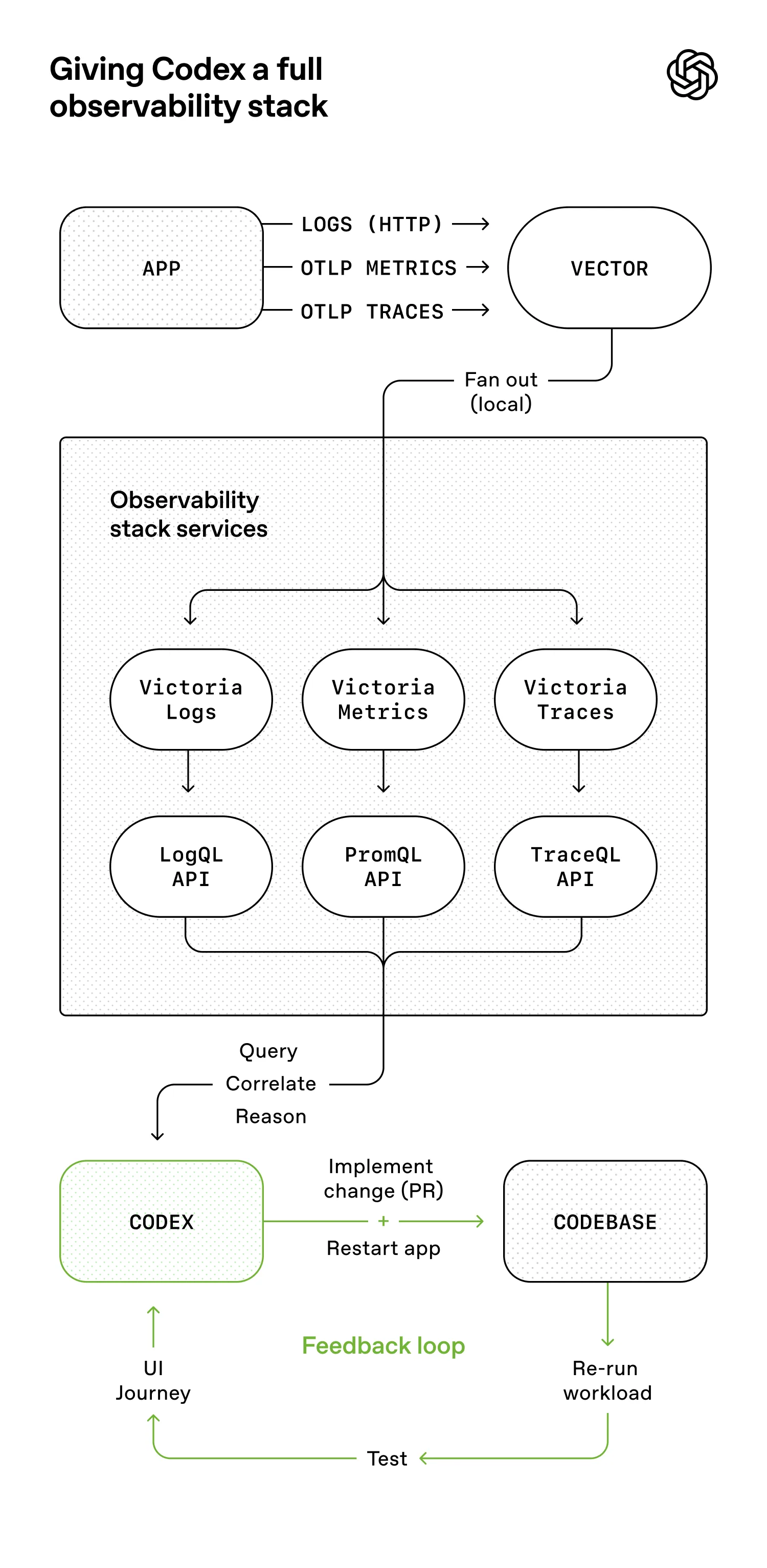
- 我们对可观测性工具也做了同样的处理。日志、指标和追踪记录会通过一个本地可观测性堆栈展示给 Codex,对任何给定的工作树来说,该堆栈都是临时的。Codex 在该应用程序的一个完全独立的版本上运行,一旦任务完成,该版本的所有内容,包括日志和指标,都会被删除。智能体可以使用 LogQL 查询日志,使用 PromQL 查询指标。有了这些情境,像"确保服务启动在 800ms 内完成"或"这四个关键用户旅程中的任何跨度都不得超过两秒"这样的提示就变得可行了。
我们将代码仓库设为记录系统
AGENTS.md # 智能体的"目录/地图",而非百科全书(约100行)
# 指向 docs/ 中的深层信息来源,实现渐进式披露
# 注入到智能体上下文中,告诉它去哪里查找信息
ARCHITECTURE.md # 顶层架构文档,描述域(domain)和包(package)的分层结构
# 定义依赖方向规则(Types → Config → Repo → Service → Runtime → UI)
# 横切关注点通过 Providers 显式接口进入
docs/
├── design-docs/ # 设计文档
│ ├── index.md # 设计文档索引,含验证状态
│ ├── core-beliefs.md # 核心理念,定义智能体优先的操作原则
│ └── ... # 其他功能/模块的设计文档
│
├── exec-plans/ # 执行计划(一等公民工件)
│ ├── active/ # 正在执行中的计划,附带进度和决策日志
│ ├── completed/ # 已完成的计划,保留历史决策记录
│ └── tech-debt-tracker.md # 技术债务追踪器,版本化且集中管理
│
├── generated/ # 自动生成的文档
│ └── db-schema.md # 数据库 Schema 文档,由工具自动生成
│
├── product-specs/ # 产品规格说明
│ ├── index.md # 产品规格索引
│ ├── new-user-onboarding.md # 具体功能的产品规格(如新用户引导)
│ └── ... # 其他产品功能规格
│
├── references/ # 参考文档(供智能体查阅的外部技术参考)
│ ├── design-system-reference-llms.txt # 设计系统参考(LLM 友好格式)
│ ├── nixpacks-llms.txt # Nixpacks 构建工具参考
│ ├── uv-llms.txt # uv Python 包管理器参考
│ └── ... # 其他技术参考,以 -llms.txt 后缀命名(针对 LLM 优化)
├── QUALITY_SCORE.md # 质量评分(对每个产品领域和架构层评分,追踪差距)
├── RELIABILITY.md # 可靠性规范(特定平台的可靠性要求)
└── SECURITY.md # 安全规范和约束AGENTS.md
## 架构
详见 [架构文档](docs/ARCHITECTURE.md)重点摘要
- 要给 Codex 的是一张地图,而不是一本 1,000 页的说明书。
- 我们不再将
AGENTS.md视为百科全书,而是将其视为内容目录。 - 一份简短的
AGENTS.md(大约 100 行)被注入到情境中,主要用作地图,并指向其他地方更深层次的真实信息来源。 - 这实现了渐进式披露:智能体从一个小而稳定的切入点开始,并被指导下一步该去哪里查看,而不是一开始就被淹没。
个人思考
不用使用@导入其他文件方式,因为启动时自动展开并加载到上下文中,会依旧导致是百科全书。需使用md语法[text](url)
ARCHITECTURE.md
如何启动项目(命令) @package.json
文件目录介绍重点摘要
- 架构文档 ARCHITECTURE.md 提供域和包分层的顶层地图。
个人思考
design-docs
重点摘要
- 设计文档已被编目和索引,其中包括验证状态和一套核心理念,定义了智能体优先的操作原则。
个人思考
docs/
├── design-docs/
│ ├── index.md # 设计文档索引(含验证状态)
│ ├── core-beliefs.md # 核心理念
│ └── ... # 其他设计文档设计文档目录,存放每个功能/模块的设计方案,通常是技术工程师关注,对应内容是:
- 架构选型(为什么用这个方案)
- 模块设计(怎么拆)
- 数据流 / 状态流
- trade-off(取舍)
- 约束(constraints)
- 核心原则(core beliefs)
"引导流程用状态机实现,数据存在 localStorage,组件拆分为 A/B/C"
各文件作用:
| 文件 | 作用 |
|---|---|
| index.md | 所有设计文档的目录索引,标注每篇文档的验证状态(已验证/草稿/已废弃),智能体从这里查找需要的设计文档 |
| core-beliefs.md | 项目核心理念,定义智能体优先的操作原则(比如"不写 YOLO 式探测数据"、"优先用共享工具包") |
| ... | 每个重要功能一份设计文档,如 new-user-onboarding.md、api-authentication.md 等 |
核心特点:
- 带验证状态:不是写完就扔的文档,index.md 会标注每篇是否仍然有效,配合 CI 自动检查。
- 供智能体查阅:智能体在实现功能前先读对应的设计文档,理解"为什么这样做"而不是盲目写代码。
- 渐进式披露:AGENTS.md 不直接包含设计内容,而是指向 design-docs/,智能体按需深入读取。 本质上是传统工程团队里的 RFC/Design Proposal 文档,但被结构化管理和机械验证,确保不会随着时间腐烂。
exec-plans
├── exec-plans/ # 执行计划(一等公民工件)
│ ├── active/ # 正在执行中的计划,附带进度和决策日志
│ ├── completed/ # 已完成的计划,保留历史决策记录
│ └── tech-debt-tracker.md # 技术债务追踪器,版本化且集中管理重点摘要
- 计划被视为一流的工件。临时轻量计划用于小幅变更,而复杂工作则记录在执行计划 codex_exec_plans中。并附带进度和决策日志,这些日志会被提交到代码仓库。活跃计划、已完成计划和已知的技术债务都已进行版本控制并集中存放,使智能体能够在不依赖外部情境的情况下运行。
- 我们严格执行这一点。专职的 linter 和 CI 作业会验证知识库的更新状况、是否已交叉链接且结构正确。一个定期运行的"doc-gardening"智能体会扫描那些不再反映真实代码行为的过时或废弃文档,并发起修复用的 Pull Request。
个人思考
docs/
├── exec-plans/
│ ├── active/ ← 正在执行的计划
│ ├── completed/ ← 已完成的计划
│ └── tech-debt-tracker.md ← 技术债务追踪器exec-plans/ 是 执行计划目录,把"要做的事"结构化管理,是项目中的一等公民(first-class artifact)。 核心思路:把计划当代码一样管理。
| 目录/文件 | 作用 |
|---|---|
active/ | 正在进行中的计划,每个计划包含任务拆解、进度记录和决策日志(为什么选A不选B),随执行过程持续更新 |
completed/ | 已完成的计划从 active 移入,保留完整历史,供未来智能体参考"之前类似问题是怎么解决的" |
tech-debt-tracker.md | 集中追踪技术债务,版本化管理,定期由"doc-gardening"智能体扫描更新 |
和传统开发的对比:
传统团队:
工程师脑子里记着计划,Slack 里讨论,会议里对齐,没有持久化
Harness 团队:
计划写成文件 → 提交到仓库 → 智能体自主读取执行 → 进度写回文件为什么这样做:
- 智能体没有记忆 — 上次对话里讨论的决定,下次运行就忘了。必须写在仓库里才能被发现
- 决策留痕 — 记录"为什么选 A 不选 B",后续智能体不会重复踩坑或推翻已有决策
- 小任务 vs 大任务 — 小改动直接做,复杂工作才写执行计划,轻重分开 本质上就是 把人类脑子里和聊天工具里的隐性知识,变成了仓库里显性的、版本化的文件。
generated
个人思考
docs/
├── generated/
│ └── db-schema.md # 数据库 Schema 文档
│ └── openapi3.md # 数据接口| 文件 | 作用 |
|---|---|
db-schema.md | 从数据库自动导出的表结构文档,包含字段名、类型、关系等 |
| 存放的是自动生成的文档,不是人工或智能体撰写的。建议使用@导入其他文件。 |
本项目数据库描述使用 prisma 构建。
生成命令:
- 格式化: prisma-format
- 生成代码: prisma-generate
schema 定义:
[prisma schema](https://www.prisma.io/docs/orm/prisma-schema/overview)
schema 内容:
@./schema.prisma核心特点:
- 由工具自动生成,不由人/智能体手写 — 比如在 CI 中运行脚本,从数据库或 ORM 定义中提取 schema,输出为 markdown
- 只读性质 — 供智能体查阅参考,不应该手动编辑(改了也会被下次生成覆盖)
- 解决什么问题 — 智能体写 SQL 或访问数据层时,需要知道表结构。与其让智能体去翻代码推理,不如直接给它一份最新的 schema 文档 和
references/的区别:
generated/ ← 自己项目的产出物,自动生成(如 db-schema)
references/ ← 第三方技术文档,手动放入(如 nixpacks-llms.txt)product-specs
个人思考
docs/
├── product-specs/
│ ├── index.md # 所有产品规格的目录索引
│ ├── new-user-onboarding.md # 新用户引导功能需求,单个功能的产品需求(做什么、为什么做、验收标准)
│ └── ... # 其他功能需求,每个功能一份,如支付流程、权限管理、数据导出等产品需求文档(PRD),它回答的问题是,主要是产品经理负责:
- 做什么 — 功能目标、用户故事
- 为什么做 — 业务背景、用户痛点
- 做到什么程度 — 验收标准、成功指标
"新用户引导流程需要3步完成,转化率目标X%"
为什么智能体需要读 PRD:
没有 PRD:
智能体拿到任务 → 只知道"做一个新用户引导" → 凭猜测实现
→ 可能做错方向、漏掉关键流程
读了 PRD:
智能体拿到任务 → 读 product-specs/new-user-onboarding.md
→ 知道要3步引导、目标转化率、必须支持跳过 → 精准实现本质上就是 把产品经理脑子里/会议里的需求,变成仓库里持久化的文件,让智能体不依赖人类口头描述就能理解产品意图。
和项目中其他文档的关系:
product-specs/ ← What(做什么) → 给智能体产品方向
design-docs/ ← How(怎么做) → 给智能体技术方案
exec-plans/ ← When/Plan(执行) → 给智能体任务拆解
docs/
├── product-specs/ ← What(做什么)
│ ├── new-user-onboarding.md 产品需求PRD:"要做新用户引导,3步完成,转化率目标X%"
│ └── ...
│
├── design-docs/ ← How(怎么做)
│ ├── new-user-onboarding.md 技术设计:"用状态机 + 3个步骤组件实现,数据存localStorage"
│ └── ...
│
├── exec-plans/ ← Plan(执行拆解)
│ ├── active/
│ │ └── new-user-onboarding.md ← 当前正在做的
│ │ ├── Step 1: 创建引导状态机类型定义(Types 层)
│ │ ├── Step 2: 实现步骤组件 StepWelcome / StepProfile / StepDone(UI 层)
│ │ ├── Step 3: 接入 localStorage 持久化(Repo 层)
│ │ ├── 进度: Step 1 ✅ Step 2 🔄 Step 3 ⬜
│ │ └── 决策日志: "选择 localStorage 而非 API 存储,因为离线场景需求"
│ ├── completed/
│ │ └── user-authentication.md ← 之前做完的,保留历史
│ └── tech-debt-tracker.md
│ ├── [高] 引导组件缺少跳过逻辑的单元测试
│ └── [低] StepProfile 组件可提取为通用表单工作流程: 智能体会先(What)product-specs 了解需求读 PRD 理解目标,再读实现方案(How) design-doc 理解技术实现方案,最后(Plan)exec-plans 分步实行方案。
产品经理意图 工程师/架构师思考 智能体执行
↓ ↓ ↓
product-specs/ → design-docs/ → exec-plans/
"做什么" "怎么做" "拆成几步做、做到哪了"智能体一次完整运行的流程:
- 读
product-specs/new-user-onboarding.md→ 理解目标 - 读
design-docs/new-user-onboarding.md→ 理解方案 - 读
exec-plans/active/new-user-onboarding.md→ 知道 Step 1 已完成,从 Step 2 继续 - 完成 Step 2,更新进度到 exec-plan
- 继续 Step 3...
references
个人思考
存放 第三方技术的参考文档,专门为 LLM 阅读优化。
docs/
├── references/
│ ├── design-system-reference-llms.txt # 设计系统参考
│ ├── nixpacks-llms.txt # Nixpacks 构建工具
│ ├── uv-llms.txt # uv Python 包管理器
│ └── ... # 其他第三方文档核心特点:
- 都是
-llms.txt后缀 — 专门为 LLM 阅读优化的纯文本格式,去掉原始文档中的导航栏、广告、JS 等噪音,只保留内容 - 第三方产出,不是自己项目的东西 — 是项目依赖的工具/库的文档摘录
- 手动放入,区别于
generated/的自动生成
为什么需要这样做:
没有 references/:
智能体要配 Nixpacks 部署 → 不知道 Nixpacks 怎么用
→ 去网上查 → 上下文里没有 → 猜着写 → 写错
有 references/:
智能体读 nixpacks-llms.txt → 知道配置格式、支持的语言、环境变量规则
→ 精准编写简单类比:就像人类工程师会把常用框架的 API 文档书签收藏起来随时查阅,references/ 就是给智能体准备的"书签夹"。
DESIGN.md
个人思考
项目的设计系统总览,定义 UI/UX 的视觉规范。它回答的问题是:这个产品长什么样、风格是什么。 大概包含的内容:
DESIGN.md
├── 色彩系统 ← 主色、辅色、语义色(成功/警告/错误)、暗色模式
├── 字体规范 ← 字体族、字号阶梯、字重
├── 间距系统 ← 4px/8px/16px... 一致的间距规则
├── 组件风格 ← 按钮圆角、卡片阴影、输入框样式
├── 布局规则 ← 页面栅格、最大宽度、响应式断点
└── 图标/插画风格 ← 图标体系、使用规范和 references/design-system-reference-llms.txt 的区别:
DESIGN.md ← 自己项目的设计规范
"我们的主色是 #1A1A2E,按钮圆角 8px"
references/design-system-reference-llms.txt ← 用的那个设计系统的原始文档
"Ant Design / Material Design 的完整 API"为什么智能体需要这个:
没有 DESIGN.md:
智能体写页面 → 凭感觉选颜色、间距 → 每次写出来风格不一致
有 DESIGN.md:
智能体写页面 → 读设计规范 → 统一用 #1A1A2E 主色、16px 间距、8px 圆角
→ 输出一致简单类比:就是前端开发中的 Design Token / Style Guide,只不过写成 markdown 让智能体能直接读取。
FRONTEND.md
个人思考
前端架构和开发指南,告诉智能体前端代码怎么组织、怎么写。 大概包含的内容:
FRONTEND.md
├── 技术栈选型 ← React? Vue? Next.js? 用的什么框架和版本
├── 目录结构 ← 组件放哪、页面放哪、状态管理放哪
├── 组件规范 ← 怎么写组件、Props 定义、命名约定
├── 状态管理规则 ← 用什么 store、什么时候用全局状态 vs 局部状态
├── 路由规则 ← 路由怎么定义、权限怎么加
├── API 调用规范 ← 怎么发请求、错误处理、类型定义
└── 构建和部署 ← 开发环境配置、构建命令、环境变量和 DESIGN.md 的区别:
DESIGN.md ← 视觉层(长什么样) → 颜色、字体、间距、圆角
FRONTEND.md ← 工程层(怎么写) → 目录结构、组件规范、状态管理为什么智能体需要这个:
没有 FRONTEND.md:
智能体写功能 → 自己决定文件放哪、用什么模式写
→ 一个文件 2000 行、状态管理混乱、和其他代码风格不一致
有 FRONTEND.md:
智能体写功能 → "组件放 components/,超过 300 行要拆分,状态用 zustand"
→ 输出结构一致、可维护简单类比:就是团队的 前端开发规范文档(通常在团队 wiki 或 Notion 里),这里直接放进仓库让智能体读。
PLANS.md
个人思考
计划管理指南,教智能体如何创建和管理执行计划。它回答的问题是:计划该怎么写、放在哪、什么流程。 大概包含的内容:
PLANS.md
├── 什么时候需要写计划 ← 小改动直接做,复杂任务才写
├── 计划文件格式 ← 模板:目标、步骤、进度、决策日志
├── 存放位置规则 ← 活跃计划放 active/,做完移到 completed/
├── 进度更新规范 ← 每完成一步怎么标记、怎么更新
└── 决策记录要求 ← 重要的技术选择必须写"为什么选A不选B"和 exec-plans/ 的关系:
PLANS.md ← 规则手册(怎么写计划)
exec-plans/ ← 实际的计划文件(按规则写出来的东西)类比:
PLANS.md ≈ 跑步比赛的规则手册(怎么起跑、怎么记圈、犯规怎么判)
exec-plans/ ≈ 运动员的实际跑步记录(跑了多少圈、配速多少)简单说:PLANS.md 是 元文档 — 它不包含具体计划内容,而是定义计划本身的规范。确保每个智能体写出来的计划格式统一、信息完整。
PRODUCT_SENSE.md
个人思考
产品感知文档,帮智能体建立"产品直觉"。它回答的问题是:这是一个什么样的产品、给谁用、什么更重要。 大概包含的内容:
PRODUCT_SENSE.md
├── 产品定位 ← 这是什么产品、解决什么问题
├── 目标用户 ← 给谁用、用户画像、技术水平
├── 核心价值 ← 最重要的体验是什么、不能妥协的部分
├── 产品原则 ← "简单优于强大"、"一致性优于灵活" 这类价值排序
├── 用户旅程 ← 用户典型使用路径、关键触点
└── 语气和风格 ← 文案风格:专业严谨? 轻松友好? 技术向?和 product-specs/ 的区别:
product-specs/ ← 单个功能的需求(具体)
"新用户引导要3步,支持跳过"
PRODUCT_SENSE.md ← 整个产品的感觉(抽象)
"我们的产品是给开发者用的,宁可专业也不要花哨"为什么智能体需要这个:
没有 PRODUCT_SENSE.md:
智能体写错误提示 → "Oops! Something went wrong 🥺"
→ 和产品调性不符
有 PRODUCT_SENSE.md:
智能体知道"面向开发者、专业风格"
→ "Error: Authentication token expired. Please re-authenticate."
→ 风格一致简单类比:就像 新员工入职时产品经理给的那段介绍 — "我们做的是什么、用户是谁、什么东西对我们最重要"。不是具体需求,而是让你有判断力的上下文。
QUALITY_SCORE.md
重点摘要
- 一份高质量的文档会对每个产品领域和架构层进行评分,并随着时间的推移追踪差距。
个人思考
QUALITY_SCORE.md 是 质量评分卡,对项目各个维度的质量打分并追踪差距。 大概包含的内容:
QUALITY_SCORE.md
├── 按产品领域评分
│ ├── 用户认证 7/10 ← 缺少 MFA 测试
│ ├── 数据导出 9/10
│ └── 新用户引导 5/10 ← 仅剩基础流程
│
├── 按架构层评分
│ ├── Types 层 9/10
│ ├── Service 层 8/10
│ └── UI 层 6/10 ← 组件缺少无障碍支持
│
└── 趋势变化
├── 认证模块:6 → 7(本周补充了边界测试)
└── UI 层:7 → 6(新增组件未覆盖 a11y)核心特点:
- 量化而非定性 — 不是"这个模块还行",而是明确的数字评分
- 追踪趋势 — 分数是变化的,能看出在改善还是退化
- 暴露差距 — 低分项就是智能体下次该优先改善的地方
和其他文档的关系:
PRODUCT_SENSE.md ← "什么对我们重要"(价值观)
QUALITY_SCORE.md ← "我们现在做得怎样"(现状)简单类比:就像汽车的 仪表盘 — 不告诉你怎么开车,但让你一眼看到哪个指标不正常,该去修了。
RELIABILITY.md
重点摘要
- 在实践中,我们通过自定义的代码检查器和结构测试来强制执行这些规则,例如,我们通过自定义 lint 静态地强制执行结构化日志记录、模式和类型的命名约定、文件大小限制,以及特定平台的可靠性要求。由于这些 lint 是自定义的,我们编写错误信息时会在智能体情境中注入修复指令。
个人思考
可靠性规范,定义特定平台的稳定性要求。 大概包含的内容:
RELIABILITY.md
├── 性能要求
│ ├── 服务启动 < 800ms
│ ├── API 响应 P99 < 2s
│ └── 关键用户旅程 任何 span 不超过 2s
│
├── 容错规则
│ ├── 重试策略 最多 3 次,指数退避
│ ├── 超时设置 请求 10s,连接 5s
│ └── 降级策略 某服务挂了怎么兜底
│
├── 可观测性要求
│ ├── 结构化日志 必须用 JSON 格式,禁止 console.log
│ ├── 告警规则 错误率 > 1% 触发告警
│ └── 追踪覆盖 关键链路必须有 trace
│
└── 平台特定约束
└── 如部署在 Vercel 的话:Serverless 函数超时 10s、冷启动优化等和其他文档的关系:
SECURITY.md ← 安全边界(不被攻击)
RELIABILITY.md ← 稳定运行(不出故障、不慢)
QUALITY_SCORE.md ← 当前质量如何(评分现状)为什么智能体需要这个:
没有 RELIABILITY.md:
智能体写功能 → 只管跑通 → 没加超时、没加重试、日志乱写
→ 线上不稳定、难以排查
有 RELIABILITY.md:
智能体知道"必须结构化日志、请求要超时、关键链路加 trace"
→ 自带 linter 强制检查,违规直接报错文章里特别提到,这些规则不仅是文档,还被 编码到自定义 linter 中 机械执行 — 比如检测到 console.log 直接报错,并在错误信息里告诉智能体该用什么替代。 简单类比:就像运维团队写的 SLO/SLA 文档 — "我们的服务承诺做到什么程度",但这里让智能体在写代码时就遵守,而不是上线后才检查。
SECURITY.md
个人思考
安全规范,定义代码必须遵守的安全边界。 大概包含的内容:
SECURITY.md
├── 认证与授权
│ ├── JWT 处理规则 token 存储、刷新、过期策略
│ └── 权限检查 每个接口必须验证权限
│
├── 数据安全
│ ├── 敏感数据 密码/密钥禁止明文、禁止提交到仓库
│ ├── 输入验证 所有外部输入必须在边界处校验
│ └── 输出编码 防止 XSS、注入
│
├── 依赖安全
│ ├── 允许的包 白名单/已知安全的依赖
│ └── 禁止的包 已知有漏洞的库
│
└── 部署安全
├── 环境变量 密钥只能通过 env 注入,禁止硬编码
└── CI/CD 合并前必须通过安全扫描文章中的安全实践例子:
"我们不使用 YOLO 式探测数据 — 我们在边界处验证数据形状,
或依赖类型化的 SDK,这样智能体不会意外地基于猜测的结构进行构建"和其他文档的关系:
RELIABILITY.md ← 稳定运行
SECURITY.md ← 安全防线
ARCHITECTURE.md ← 结构约束(依赖方向、分层规则)简单类比:就像公司的 信息安全制度 — "密码不能明文存、外部输入必须校验、密钥不能提交到代码",只不过不是贴在墙上给人看的,而是写成文档让智能体在写代码时遵守,并通过 linter 自动检查。
目标是智能体的可读性
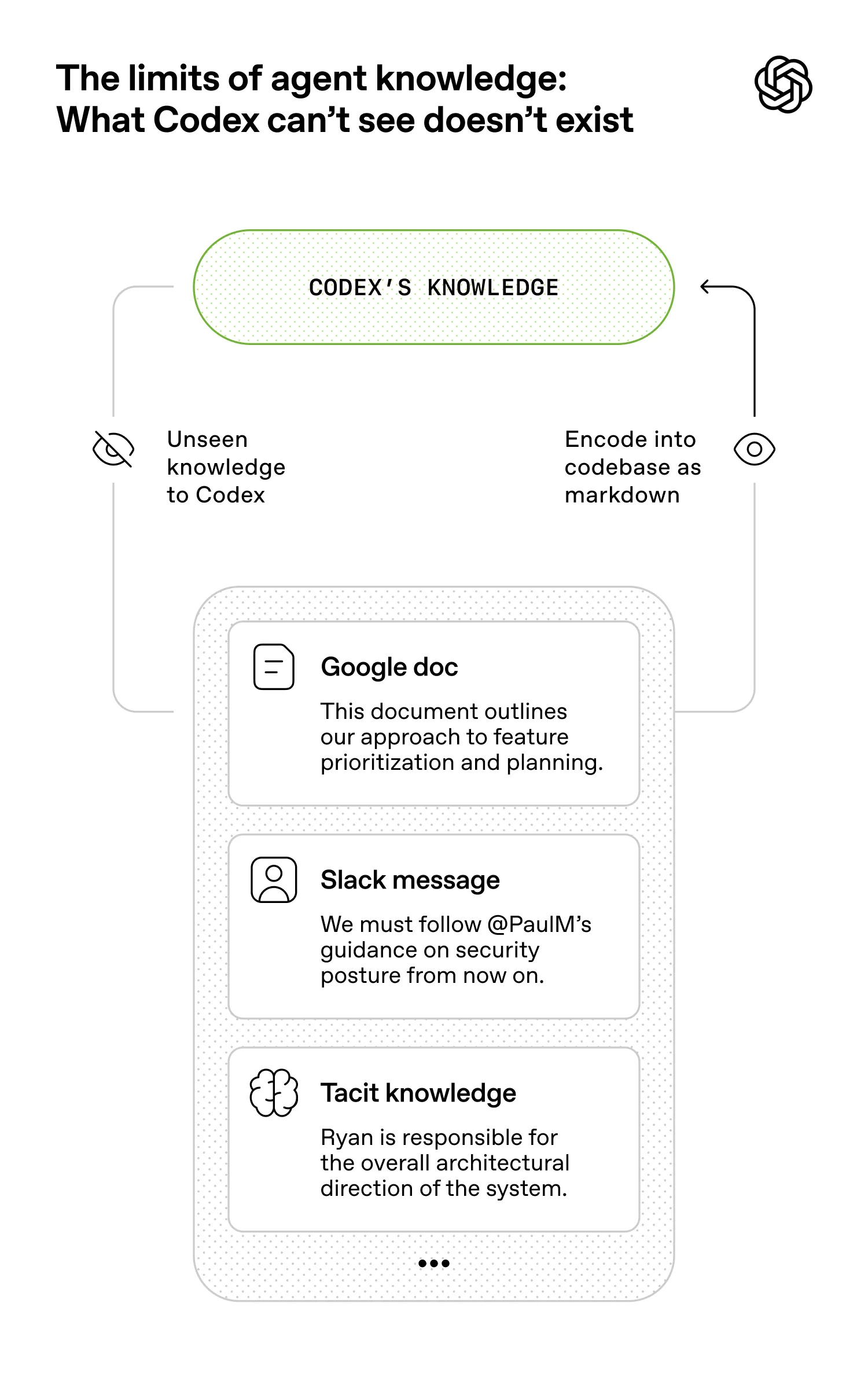
- 我们人类工程师的目标也是让智能体能够直接从代码仓库推理出完整的业务领域。
- 代码仓库本地的、已版本化的工件(例如,代码、Markdown、模式、可执行计划)就是它所能看到的全部。
- 在某些情况下,让智能体重新实现部分功能子集比绕过公共库中不透明的上游行为更便宜。例如,我们没有引入通用的 p-limit 风格包,而是投入使用了我们自己的带并发的 map 辅助函数:它与我们的 OpenTelemetry 仪表紧密集成,具备 100% 的测试覆盖率,并且其行为完全符合我们的运行时预期。
规范架构与品味
- 通过强制执行不变量,而非对实施过程进行微观管理,我们令智能体能够快速交付,而且不会削弱基础。
- 智能体在具有严格边界和可预测结构的环境中最为高效,因此我们围绕一个严格的架构模型构建了该应用。每个业务域都划分为一组固定的层,依赖方向经过严格验证,并且仅允许有限的一组边。这些约束是通过自定义的 linter(当然是由 Codex 生成的!)和结构测试机械地强制执行的。
- 在每个业务领域内(例如应用设置),代码只能"向前"依赖于一组固定的层(Types → Config → Repo → Service → Runtime → UI)。横切关注点(认证、连接器、遥测、功能标志)通过一个单一的显式接口进入:Providers。其他任何内容都不被允许,并将通过自动化方式强制执行。
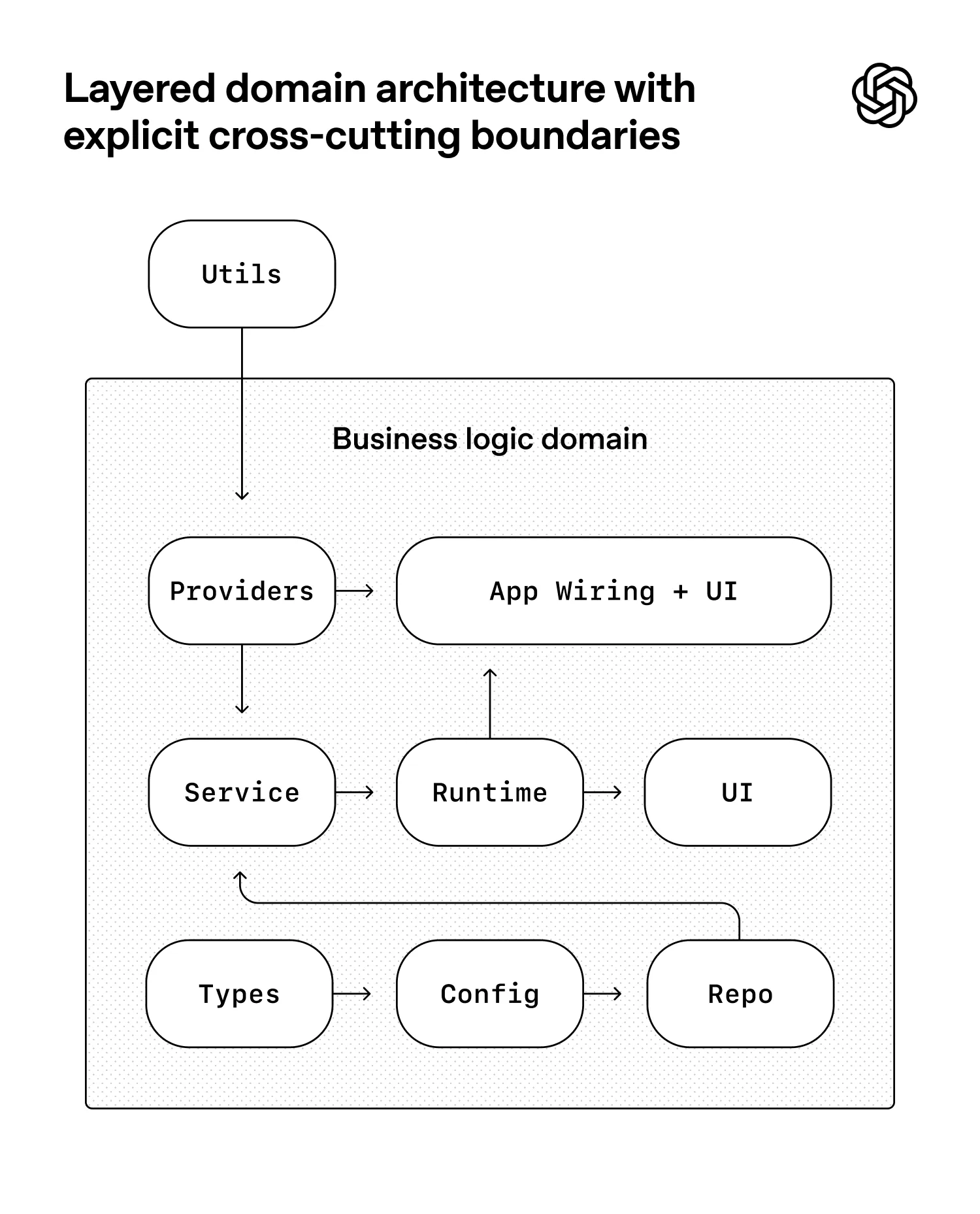
- 对于编码智能体来说,这是一个早期的先决条件:有了约束,速度才不会下降,架构才不会漂移。
- 我们通过自定义 lint 静态地强制执行结构化日志记录、模式和类型的命名约定、文件大小限制,以及特定平台的可靠性要求。由于这些 lint 是自定义的,我们编写错误信息时会在智能体情境中注入修复指令。
- 你非常重视界限、正确性和可重复性。在这些边界内,你允许团队或智能体在解决方案的表达方式上拥有很大的自由。
- 生成的代码不总是符合人类的风格偏好,这也没关系。只要输出是正确的、可维护的,并且对未来的智能体运行而言清晰易读,就可以算作达标。
个人思考
域(Domain)
**域 = 业务领域,**即按功能划分的模块。比如一个应用可能有这些域:
app-settings(应用设置)user-management(用户管理)billing(计费)notifications(通知)
包(Package)
包 = 域内的分层。每个域内部被强制划分为固定的几个层级(包),依赖方向只能"向前":
Types → Config → Repo → Service → Runtime → UI
↑ ↑
最底层(纯类型定义) 最上层(界面展示)具体含义:
| 域内部的层级 | 职责 | 例子 |
|---|---|---|
| Types | 纯类型/接口定义,零逻辑 | interface User { id: string } |
| Config | 配置常量、环境变量 | DATABASE_URL, MAX_RETRIES |
| Repo | 数据访问层,与数据库/外部存储交互 | findUserById(), saveOrder() |
| Service | 业务逻辑层,编排 Repo 调用 | processOrder(), authenticateUser() |
| Runtime | 运行时/服务启动、依赖注入 | 服务器初始化、路由注册 |
| UI | 用户界面,展示层 | React 组件、HTML 模板 |
依赖只能单向流动:Types 可以被任何层引用,但 UI 不能引用 Types 之外的层反向依赖。比如: ✅ Service → Repo (允许) ✅ UI → Types (允许) ❌ Repo → Service (禁止,反向依赖)
横切关注点(如认证、日志、功能开关)不直接穿插在各层中,而是通过一个统一的 Providers 接口注入:
Providers(认证、遥测、功能标志...)
↓ 注入
Types → Config → Repo → Service → Runtime → UI为什么这样做: 对 AI 智能体来说是必要前提,原因:
- 防止架构漂移 — 智能体会复制已有模式,如果模式混乱,混乱会指数级放大
- 可机械执行 — 自定义 linter 和结构测试能自动检测违规,不需要人工审查。流程实现制度。
- 减少上下文需求 — 智能体只需知道"我在改 Service 层",就知道能依赖什么、不能依赖什么 简单类比:这就像城市分区规划——住宅区、商业区、工业区各归其位,道路单向通行。不限制具体怎么盖楼(实现自由),但严格限制什么能建在哪里(边界约束)。
吞吐量改变了合并的理念
- 尽量减少阻塞合并门。测试偶发失败通常通过后续重跑来解决,而不是无限期地阻碍进展。
- 在一个智能体吞吐量远超人类注意力的系统中,纠错成本低,而等待成本高。
"智能体生成"实际上意味着什么
- 智能体的产出包括:
- 产品代码与测试
- CI 配置和发布工具
- 内部开发者工具
- 文档和设计历史
- 评估框架
- 审阅评论和回复
- 管理代码仓库本身的脚本
- 生产仪表板定义文件
- 我们优先处理工作,将用户反馈转化为验收标准,并对结果进行验证。当智能体遇到困难时,我们将其视为一个信号:识别缺失的内容 — 工具、指导、约束、文档 — 并将其反馈到代码仓库中,始终由 Codex 自己编写修复。
- 验证代码库的当前状态
- 重现已报告的漏洞
- 录制一个演示故障的视频
- 实施修复措施
- 通过运行应用程序来验证修复
- 录制第二个视频,演示解决方案
- 打开 Pull Request
- 回应智能体和人类反馈
- 检测并修复构建故障
- 仅在需要判断时才交由人工处理
- 合并更改
熵与垃圾收集
- 我们开始将我们称为"黄金原则"的内容直接编码到代码仓库中,并建立了一个循环清理流程。这些原则是带有主观意见的机械规则,旨在保持代码库的可读性和一致性,以便将来运行智能体。例如:
- 我们更倾向于使用共享的实用程序包,而不是手工编写的辅助工具,以便将不变式集中管理;
- 我们不会使用"YOLO 式"探测数据 — 我们会验证边界,或依赖类型化的 SDK,这样智能体就不会意外地基于猜测的结构进行构建。我们会定期运行一组后台 Codex 任务,扫描偏差、更新质量等级,并发起有针对性的重构 Pull Request。其中大多数都可以在一分钟内完成审查并自动合并。
- 技术债务就像一笔高息贷款:不断地以小额贷款的方式偿还债务,总比让债务不断累积,再痛苦地一次解决要好得多。
- 我们能够每天发现并解决不良模式,而不是让它们在代码库中传播数天或数周。
个人思考
- 多使用开源工具,而不是手工编写的辅助工具。
- 黄金法则示例:safety-first,Ai生成示例:
# .claude/rules/golden-principles.md
## 黄金原则
### GP-001: 共享工具优先
- ✅ 优先使用 `@/utils/common` 中的工具函数
- ❌ 禁止在各组件中重复实现相同的工具函数
### GP-002: API 调用统一入口
- ✅ 所有 API 调用必须通过 `@/services/api/` 中的服务
- ❌ 禁止在组件中直接使用 axios
### GP-003: 类型边界验证
- ✅ API 返回值必须使用 TypeScript 类型或 Zod 验证
- ❌ 禁止使用 `any` 类型接收 API 响应
### GP-004: 状态管理规范
- ✅ 跨组件状态使用 Pinia stores
- ✅ 组件内状态使用 ref/reactive
- ❌ 禁止通过 props drilling 传递超过 2 层
### GP-005: 枚举模式
- ✅ 使用 CLAUDE.md 中定义的枚举模式
```typescript
export const statusEnum = {
Active: 'active',
Inactive: 'inactive',
options() { return [...]; },
label(value) { return ...; },
} as const;GP-006: 文件大小限制
- 单文件不超过 500 行
- 超过 300 行应考虑拆分 GP-007: 组件命名
- 页面组件: PascalCase + 路径对应
- 共享组件: PascalCase + 功能前缀
- 工具函数: camelCase
## 我们仍在学习的内容
+ 随着时间的推移,模型的功能不断增强,这一系统将如何演变。
+ 显而易见的是:**构建软件仍然需要纪律,但纪律更多地体现在支撑结构上,而不是代码上。**
+ **我们当前最棘手的挑战集中在设计环境、反馈回路和控制系统方面**,帮助智能体实现我们的目标:大规模构建和维护复杂、可靠的软件。